2024年Flink从入门到就业全栈教程 部署、集群与项目实战
引言
随着大数据实时处理需求的激增,Apache Flink作为业界领先的流处理框架,已成为数据工程师和开发者的必备技能。本教程旨在系统性地指导你从零开始掌握Flink,涵盖基础概念、环境部署、集群搭建,直至将项目从本地测试顺利部署到生产环境,为你的学习和就业之路奠定坚实基础。
第一部分:Flink基础入门
1.1 核心概念解析
Flink的核心优势在于其统一的流批处理能力。你需要首先理解几个关键概念:
- DataStream API:用于处理无界数据流(实时数据)。
- DataSet API(已逐步向流批一体演进):用于处理有界数据集(批处理)。
- 状态管理:Flink强大的状态后端支持,是处理有状态计算的关键。
- 时间语义:Event Time、Processing Time和Ingestion Time的区别与应用场景。
- 窗口操作:滚动窗口、滑动窗口、会话窗口等,是流处理的核心算子。
1.2 开发环境搭建
- 安装Java:确保安装JDK 8或11(推荐11),并配置好
JAVA_HOME环境变量。 - 安装IDE:推荐使用IntelliJ IDEA,安装Scala插件(如需使用Scala API)。
- 获取Flink:从Apache官网(https://flink.apache.org/)下载最新稳定版(如1.18.x)的二进制包。
- 本地启动:解压后,在
bin目录下运行./start-cluster.sh(Linux/Mac)或start-cluster.bat(Windows),即可启动一个单机本地集群。访问http://localhost:8081可打开Web UI。
第二部分:Flink部署详解
2.1 本地测试与开发
本地模式是最快速的验证方式。你可以在IDE中直接运行main方法,Flink会以嵌入模式执行。此模式适合调试业务逻辑和单元测试。
2.2 集群部署(Standalone模式)
这是最简单的生产级集群部署方式,适合中小型公司或学习环境。
- 节点规划:准备至少3台Linux服务器(1个JobManager,2个TaskManager)。
- 基础软件服务:
- Java:所有节点统一安装相同版本的JDK。
- SSH免密登录:配置JobManager到所有TaskManager的SSH免密登录,方便脚本启动。
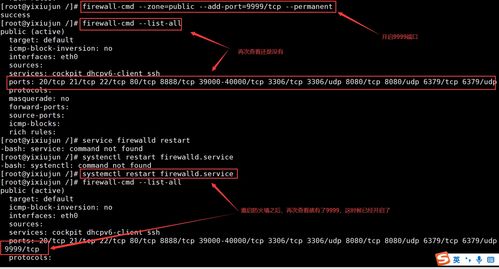
- 网络与防火墙:确保节点间网络畅通,开放所需端口(如8081用于Web UI,6123用于RPC)。
- 配置与启动:
- 修改
conf/flink-conf.yaml:设置jobmanager.rpc.address为主JobManager的IP,配置taskmanager.numberOfTaskSlots(每个TaskManager的槽位数)。
- 修改
conf/workers文件:列出所有TaskManager的主机名或IP。
- 在JobManager节点运行
bin/start-cluster.sh启动整个集群。
2.3 高级集群部署(On YARN/K8s)
对于大型企业生产环境,资源管理更推荐使用YARN或Kubernetes。
- YARN模式:Flink作为YARN的一个应用提交,由YARN负责资源调度。命令示例:
./bin/flink run -m yarn-cluster -ys 2 -ynm MyFlinkJob ./examples/streaming/WordCount.jar。 - Kubernetes模式:这是云原生时代的主流。需先部署K8s集群,然后使用Flink的K8s部署描述文件或Operator进行部署,具备极佳的弹性伸缩能力。
第三部分:从项目源码到生产部署实战
3.1 项目开发与本地打包
- 使用Maven或SBT创建项目,依赖Flink相关库(如
flink-streaming-java)。 - 编写核心业务逻辑(如数据清洗、实时聚合)。
- 使用
mvn clean package打包生成一个包含所有依赖的JAR文件(Uber Jar)。
3.2 提交作业到集群
- 命令行提交:在生产集群的JobManager节点,使用命令
./bin/flink run -c com.your.MainClass /path/to/your-job.jar。 - 通过Web UI提交:访问集群Web UI,直接上传JAR包并配置主类与参数。
- 通过REST API提交:便于集成CI/CD流水线,实现自动化部署。
3.3 生产环境关键考量
- 高可用(HA)配置:配置ZooKeeper来实现JobManager的故障转移,确保作业持续运行。
- 状态后端与检查点:生产环境务必配置可靠的状态后端(如RocksDB)和定期的检查点(Checkpoint),用于故障恢复。这是保证数据一致性和Exactly-Once语义的基石。
- 监控与告警:集成Metrics系统(如Prometheus + Grafana),监控作业吞吐量、延迟、背压等关键指标,并设置告警。
- 资源与性能调优:根据数据量调整并行度、内存配置、网络缓冲区大小等。
- 依赖管理:确保生产集群的类路径与开发环境一致,特别是第三方Connector(如Kafka、HBase)的版本。
第四部分:学习路径与就业建议
- 学习路径:核心API → 状态与容错 → 时间与窗口 → Connector开发 → 部署与调优 → 源码阅读。
- 实战项目:尝试构建一个端到端的实时数据管道,如“实时日志分析系统”或“实时电商风控系统”。
- 就业准备:深入理解上述部署和生产化过程,能让你在面试中脱颖而出。企业不仅需要会写Flink代码的人,更需要能保障作业在复杂生产环境中稳定高效运行的工程师。
###
掌握Flink的部署与集群管理,是从学习者迈向合格大数据开发工程师的关键一步。本教程提供了一个从本地到生产的清晰路线图。技术的精进在于持续的实践与,让我们一起动手,在真实的数据流中锤炼技能,迎接大数据实时处理的浪潮。
如若转载,请注明出处:http://www.vknhew.com/product/25.html
更新时间:2026-06-19 10:34:08